口述/孫培然‧彙整/CIO編輯室

醫院的數位轉型包括兩大重點,第一個是 OLTP(OnLine Transactional Processing)為線上交易處理,也就是醫院資訊系統(HIS),第二個是 OLAP(OnLine Analytical Processing)為線上分析處理,也就是透過大數據及 AI 所提供的資料進行分析。
最近幾年我一直在宣導如何變成微服務。大家都知道,OLAP 的資料量遠大於 OLTP 系統,既然 OLTP 都已經在變成微服務了,OLAP 的單體難道不需要微服務嗎?這也是未來資料網格(Data Mesh)在醫療數位轉型中扮演重要角色。
Client/Server 架構的問題
台灣的 HIS 因為 90% 以上都是屬於 Client/Server 架構,現在遇到很多問題,包括系統老舊,開發人員短缺;工具老舊,支援 AI 應用,事倍功半;使用者介面整合度差,不夠友善。還有系統疊床架屋,系統整合難度高;系統連結過多且不夠明確,穩定性不佳;加上資料沒辦法整合,成為散落在各地的資訊孤島。
HIS 的效能差怎麼辦?只能先換硬體,解決燃眉之急。如換比較高檔的主機伺服器,加大 CUP 效能,擴大記憶體,硬碟改為 SSD 提升 I/O 效能,提升網路頻寬。
但更換硬體「只能治標不能治本」,但為什麼醫院遲遲不敢將 HIS 汰舊換新?
主要的原因包括,新、舊資料庫的結構可能不一樣,存在著一對多或者多對一,甚至多對多的問題,所以舊系統與新系統的資料交換,可能就會產生很多問題,而新舊資料交換,又要確保不會影響舊資料的效能跟穩定性,確實是很困難。
此外,很多資料必須要經常跨新、舊資料庫的去查詢,速度變得非常的慢。一旦新的資料庫要異動,舊的資料庫也要同步異動,幾乎是要達到即時性的要求,所以考慮到新、舊資料庫要並存,又要考慮到多個資料庫參與一筆Transaction的兩階段提交(two-phase commit)的難度,更容易產生一些問題。
因為前述考量,所以很多醫院都遲遲不敢更換HIS系統,因為要換就是全部要換成新系統,一夕之間要把舊系統淘汰掉。但想要做到一次到位,資料、軟體及硬體都要要求沒有突發的問題產生,對 IT 業界都已經是天方夜譚的要求了,更何況還得讓眾多病人跟醫護人員面對新的流程及新的操作界面熟悉度,這些光是想都是問題了,往往上線的那一天就是「亂、亂、亂!」,也導致很多醫院都不敢輕易嘗試。
清理資料困難重重
至於 OLAP 方面的問題,很多醫院會把他們的 HIS的資料庫 ETL(Extract-Transform-Load;擷取、轉換和載入)到大數據中心,這個工作非常的繁重,而且需要很多跨單位的支持,比如說 HIS 系統要由資訊中心的人員 ETL 到資料倉儲(Data Warehouse),但資料是否正確,則可能要透過大數據中心或其他單位來做清理及檢測。
這樣的往返就會造成很多困難,如果雙方溝通不良就會形成很多爭執。很多資料從 HIS 轉到資料倉儲,有些系統沒有做好資料輸入的把關機制,導致產生許多垃圾資料(Garbage Data),難道就讓這些資料「Garbage in, garbage out ?」。所以資料的品質跟資料的正確性,就要取決於我們怎麼去清理。
但誰來清理這些資料呢?絕對不會是資訊中心,因為資訊中心的IT人員不懂醫療領域知識(Domain Knowledge),所以就需要由懂得醫療專業領域的人來清理這些資料。以中國附醫為例,資料清洗(Data Cleaning)是交由大數據中心來負責主導,因為大數據中心有專門一群醫療知識背景的人員會幫忙清理相關資料,如果需要更深入的清洗,他們就會找其他單位來協助。
但接下來又會遇到其他的瓶頸,從 HIS 要 ETL 到資料倉儲,就一定要不停的抓取線上的資料,這樣子會造成原來的 HIS 資料庫太過於忙碌,導致前台的使用效能變慢或者不夠穩定。如果不這樣做,可能只能利用離峰時間或者是隔一段時間才去執行一次資料轉檔,也因此常常被使用者笑說:「這些資料是提供給考古學系用的嗎?」,因為這些資料都已經是一個月前所發生的資料了,現在才來分析不夠即時,往往就是從 HIS 轉到資料倉儲的瓶頸之一。
[ 加入 CIO Taiwan 官方 LINE 與 Facebook ,與全球CIO同步獲取精華見解 ]
但就算資料已經轉過來了,也可能會有其他瓶頸,如資料倉儲的投入成本太高,建置不易,而且沒辦法很靈活的去運用系統滿足營運管理需求,使用傳統技術很難展現醫院的敏捷性,在效能、資源分配上,都會遇到很多應用的瓶頸。
要從資料源(Data Source)延伸到經營管理應用,就會因為資料架構太過於複雜,要花費非常大的時間與人力成本才能達到,而且還必須要有跨單位或是懂相關知識領域的人來清理這些資料,這都不是大數據中心或者資訊中心有辦法去統籌,產生瓶頸也就在所難免。
以中國附醫的HIS資料庫要 ETL 到資料倉儲為例,大概花了三年時間才把 300 萬病人 17 年的就醫資料,大概有一百多個資料集及 16 萬的基因資訊,轉到資料倉儲。資料轉完以後,在做資料清洗時,一旦發現資料可能轉錯了,就要從頭再走一遍,一來一往的轉,足足轉了三年。
這還只是從 HIS 的資料庫轉到資料倉儲而已,醫院還有許多臨床研究中心的資料庫,比如說中風、外傷、胸痛、腎臟及心臟…等中心,這些資料庫都要試著轉到資料倉儲。但卻遇到了一個問題,各科臨床研究中心的醫學領域太深奧了,就單單靠資訊中心或者大數據中心來負責清理資料,是沒辦法通盤瞭解各科臨床研究中心整個資料的來龍去脈,就沒辦法很順利的移轉。然而,醫院想要透過資料驅動(Data-Driven)來做到數位轉型,建立一個以病人為中心,可以提供即時資料的神經網絡,就變得窒礙難行。
傳統資料平台的瓶頸
除了醫院面臨兩大痛點之外,傳統式資料庫也會遇到瓶頸。傳統資料平台的演進,若是企業級的資料倉儲(Data Warehouse),主要是提供商業智慧(Business Intelligence)的研究分析,後來又有人提出資料湖(Data Lake)的概念,就是以資料湖為代表的大數據生態系統(Big Data Ecosystem),更進階的是雲端資料平台(Cloud Data Platform),就是以雲端資料平台,包含即時資料流架構、整合批量(Batch)與流處理(Stream Processing)的框架、並結合雲端存儲、流水線以及機器學習能力所建立的系統。
不管是哪一種傳統資料平台都是屬於集中式,而且負責的人員都與領域無關,如中國附醫的資訊中心或者大數據中心的工程師都是 IT 人員,所以不管是哪一種傳統資料平台,都是以集中式的概念,形成一個比較嚴格劃分的資料倉儲。這種方式往往需要很多的技術,而這麼多的技術可能會形成很龐大的技術債。
也就是說,在資料的生產者與使用者之間,會有一個分佈在醫院無數角落,在各種不同專業領域對資料進行轉換、清洗和擴充,為資料的需求者,提供報表、分析、機器學習平台及批次的龐然大物。
[ 瀏覽孫培然所有文章 ]
這樣的特性造成傳統資料庫產生一些問題,就是無處不在的資料和來源擴散,加上組織的創新議題和使用者不斷的激增,會讓集中式的資料庫沒辦法應付生產者或使用者所提的需求。
此外,傳統資料平台裡面會包括許多次專科的醫療知識領域,比如有神經外科、有外傷,有腎臟科、心臟內科,這些資料的來源都是屬於各科的專業領域,資訊中心或是大數據中心的工程師都不懂,卻要這些人來維護管理這些資料。
所以「資料中心化」以後,就會產生資料所有權的問題,也就是讓不懂資料專業領域的人來管理資料庫,等於就是外行領導內行。尤其,是在醫院這種很多次專科的環境下,資料更為多樣化,也導致傳統資料平台已經不敷使用。
傳統資料平台還會有職責劃分不當的問題,如資料生產者可能是醫師,將醫囑開立到系統裡面,大數據工程師再透過擷取、處理、服務的方式,儲存在傳統資料平台。但這些組織都是孤立的,如大數據工程師只有大數據工具的技術專長,缺乏業務領域的知識,卻要管理這麼多不同專業領域的資料。
而使用者可能是醫師,也可能是研究人員,知道資料的業務潛力,也更清楚的知道需求跟資料的品質,但卻插不上手,只能單純的由大數據中心提供資料。所以從利益、責任和能力分散在三個不同的生產者、大數據工程師以及使用者的身上,導致很多的摩擦、挫折和誤解。
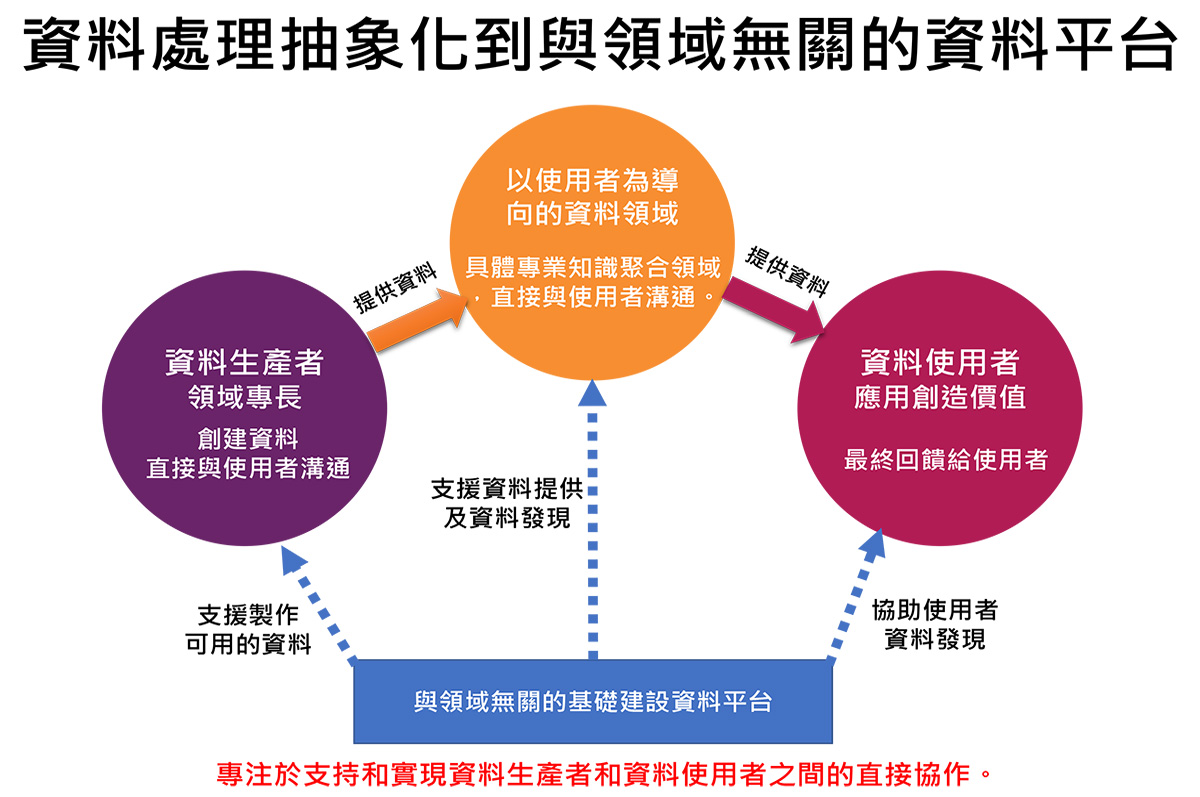
資料處理應設法抽象化
所以應該要怎麼做?首先,大數據工程師擷取、處理、服務的資料,必須把它抽象化,抽象到跟領域無關,資料要怎麼創建,就由資料生產者或者資料使用者來執行,大數據工程師只提供資料處理的工具,專注在支持跟實現資料生產者和資料使用者之間的直接協作。
這種與領域無關的一個自助資料服務平台,或許才有辦法解決傳統資料庫的瓶頸跟問題。因為現在的資料生產者跟資料使用者,是多元性且多變化性。他們具有領域的專業知識,瞭解資料的含義。資料的使用者瞭解資料的業務潛力,可以清楚的描述資料的需求,以及包括資料品質的相關需求。
大數據工程師則是單純性且變化少,只有 IT 的專業知識。所以我們應該把資料的解讀跟生產使用,歸還給資料生產者跟資料使用者層面,才能夠達到平衡。
總而言之,傳統資料平台的主要問題瓶頸,在於因為它是單體式的集中化架構,所以難以啟動,資料源及資料使用都難以規模化,自然就難以實現資料的商業價值。
(本文授權非營利轉載,請註明出處:CIO Taiwan)