讓 AI 依照企業需求部署
本文彙整了生成式 AI 大環境的演變、企業態度以及資安考量等,最後對企業應如何導入這類生成式 AI Chat Tools 進行分析並提供建議。
文/王文泰

ChatGPT 在 2022 年 11 月底引爆了整個人工智慧中生成式 AI 的發展,其功能從寫程式、程式 Debug、寫詩寫故事、寫學術論文、語言翻譯、語音對話、摘要文件內容、寫作寫劇本、角色扮演與專家應答…等。 這一年來,已經誕生許多新的 AI 模型與以及各領域的應用。另一方面,其所帶來的商業資料洩密與資安等問題,也讓許多企業對於導入這些 AI Chat 軟體工具卻步。
以下將針對企業如何導入這類生成式 AI Chat Tools 進行分析並提供建議。
大環境 ─ 各國針對 ChatGPT AI 的法規與管制
1. 美國:
OpenAI 執行長 Sam Altman 2023 年 5 月在參院聽證會表示,對日益強大的人工智慧帶來的系統風險,他提議成立一個美國或全球監管機構,為強大的 AI 系統進行監管,避免 AI 模型狂放的自我複製和滲透。白宮科技政策辦公室徵求公眾意見,包括標準、法規、投資、改善信任以及安全實踐等制訂戰略。2023 年 10 月底,美國總統拜登簽署一項行政明令,建立 AI 安全法則,內容包括:
- 企業開發對國安、經濟有風險的模型需告知政府,並分享安全測試結果;
- 保護民眾隱私,保障消費者/病患/學生與勞工權益;
- 促進創新與競爭,提升美國的國際領導力,強化國際合作
- 確保政府能負責任且有效的使用 AI。
2. 歐盟:
2023 年 6 月,歐洲議會投票通過「人工智慧法案」的立法草案,這是西方第一部全面的 AI 法規,包括:生成式 AI 系統的製造商,必須採取保護措施,防止生成非法內容,公司必須標記 AI 生成的內容,以防止 AI 被濫用傳播謊言,製造商必須提供摘要,揭露用來訓練 AI 模型的資料來源,製造商要向內容創作者提供分潤方案…等。
- 德國:要求 OpenAI 遵守歐盟 GDPR,特別在收集與處理用戶資料時,要保證透明與合法性。
- 法國:提出關於 AI 的倫理以及法律建議,包括建立一個獨立監管機構,負責監管與審查 AI Chatbot 的合規與 Responsibility。
- 義大利:2023 年 3 月曾經禁止使用 ChatGPT,4月有條件開放。要求告知 ChatGPT 運行所需資料背後的方法與邏輯,提供工具可以讓用戶糾正或刪除,以及年齡驗證相關系統。
3. 英國:
於 2023 年 10 月底召開 AI 安全峰會,包含美國、英國、中國與會的 28 國代表,簽署「布萊切利宣言(Bletchley Declaration)」,全球推動 AI 安全議題方面的合作,降低 AI 潛在風險,提升 AI 資訊透明度,並建立合適的評估指標與安全測試工具,強調 AI 可解釋性、可負責性和可信賴性。
4. 中國:
中國政府對 ChatGPT 進行連接限制。2023 年 4 月公布規則草案,要求 AI 聊天機器人製造商遵守中國的審查。同時間,中國企業與學術界發展中國的生成式 AI 以及大語言模型(LLM),例如:ChatGLM、百度文心一言等。
5. 台灣:
國科會 2023 年 8月研訂「行政院及所屬機關使用生成式 AI 參考指引」,規範業務承辦人需就風險進行客觀且專業的最終判斷、製作機密文書由業務承辦人親自撰寫/禁止使用生成式 AI、不得提供公務機密資料、遵守資通安全/個人資料保護/著作權…等。
企業態度 ─ 對 ChatGPT 的導入態度與考慮
根據 Fortune 的報導,ChatGPT 這類生成式 AI 工具可以增加效率與生產力,但也有許多公司考量資料洩密、程式碼外洩與資安風險,選擇禁用 ChatGPT。這些公司包括三星(Samsung)、蘋果(Apple)、高盛、花旗銀行…等 Fortune 500 的大企業。
[ 加入 CIO Taiwan 官方 LINE 與 Facebook ,與全球CIO同步獲取精華見解 ]
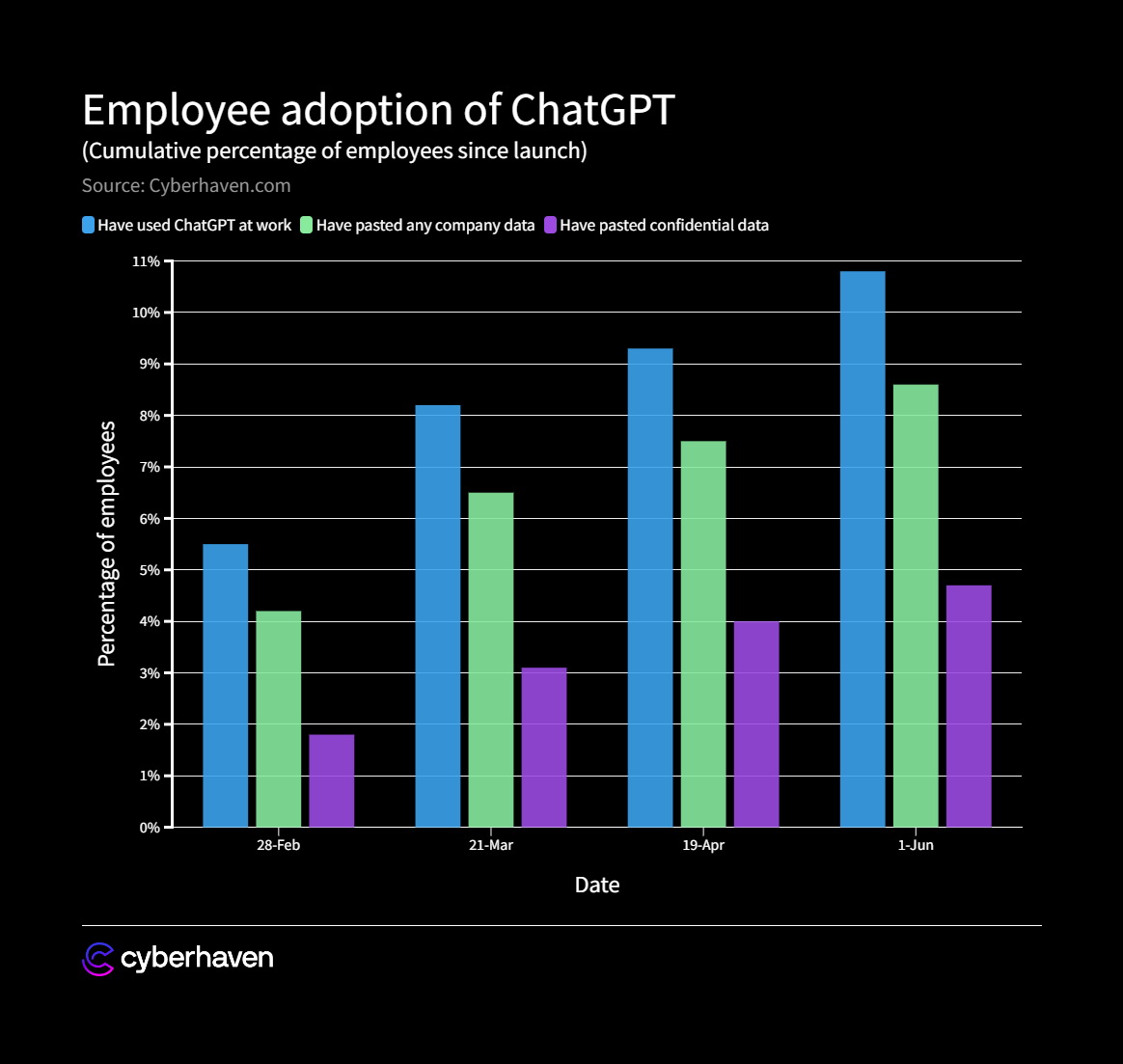
然而,這麼好用的工具,企業禁止使用,員工就不會使用它嗎?根據 cyberhaven 的分析,10.8% 的員工在工作場合使用過 ChatGPT,而 8.6% 員工曾將公司資料貼到 ChatGPT。員工要規避企業的限制也非常容易,他們可以透過手機、透過自己的電腦,甚至在家裡使用這個好用的 AI 工具。
企業怕資料外洩,那麼生成式 AI 的資料「有哪些」又「放在哪裡」?
目前使用 ChatGPT 等這類的生成式 AI Chat 工具,會有下面三種 Components:
- Prompt:使用者輸入(或透過 API 拋轉)相關的提示 Prompt(問題、請求、程式、想要進行摘要的內容、想要翻譯的文件…等),這些 Prompt 會放置到 LLM(大語言模型)去執行產生結果。
- LLM(Large Language Model):大語言模型是核心,由於訓練需要大量的資料以及很大的運算能力,其成本非常昂貴,目前在排行榜上前幾名的 LLM,大多由超級大企業與研究單位投入鉅資進行訓練與建立。大部分為「Proprietary」,表現的形式是,LLM Server 放在該公司雲端,用戶使用時,必須將 Prompt 輸入或透過 API 拋轉到這些公司的雲端 LLM 上才能執行。另外,還有一些 LLM 是無法進行商業行為。最後,有少數的 LLM 可以開放企業或組織下載,並允許商業化應用(如 Meta LLaMA 2)。
- Data:大語言模型需要大量的資料進行訓練,這部分大部分採用了網路上的 Open Data 或是被授權的資料等;另外,企業也可以 Fine tune training 自己的 Data,則這些 Data 會透過 Fine tune Model 方式進行放置。

● OpenAI 的 Data security
在 OpenAI 公司的官網上說明,它們已經合規於歐盟 GDPR 以及美國 CCPA。另外,OpenAI API 服務,經過第三方資安評估,也已經合規於 SOC 2 Type 2。(https://openai.com/security)
[ 推薦閱讀:與 ChatGPT 共享機敏商業資訊非常冒險]
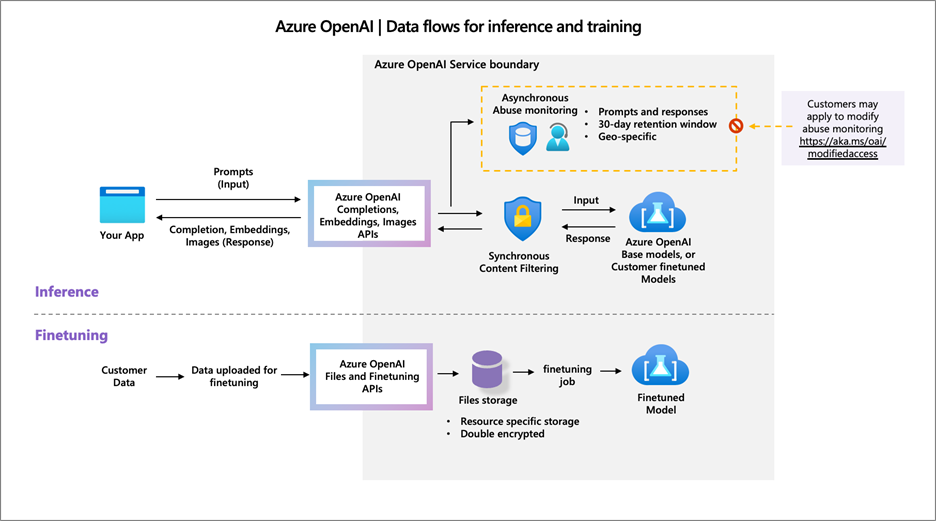
另外,在微軟官網上,Azure OpenAI Data flows 上,可以看到包含微軟以及 Open AI 等公司,針對其客戶輸入的資料,進行資料流的梳理並進行分析,用以確保企業的資料安全性。其中 Prompt & Response 會有 30 天的時間留在 OpenAI 公司的 Server 裡,其客戶可以透過網站進行調整修改。這部分的作法雖然還是有一些爭議與討論(有興趣讀者可以看這一篇〈Azure OpenAI Content Filtering and Abuse Monitoring with Microsoft Sentinel〉,https://rodtrent.substack.com/p/azure-openai-content-filtering-and),這是一個資料保護的重要進展,相對 ChatGPT 剛推出來的時候 2022 年末以及 2023 上半年。
企業使用生成式 AI Chat 工具:GO or NO-GO?
經過這一年的時間的發展,企業決策者需要關注下面這幾點:
- AI 發展的飛快成長:尺度不是每年來算,而是每天每周每月的快速的成長。越晚導入,企業就面對更多競爭。
- 公司政策禁用,員工還是會用:就像是沒法禁止員工使用瀏覽器上網。
- 各國法規開始要求 AI 廠商,而 AI 廠商也開始重視 AI Responsibility。
- 微軟 Copilot and Google AI workspace 已經導入 微軟、Google 辦公室文書軟體、瀏覽器、郵件軟體、搜尋引擎…等,企業想要檔也擋不住。
根據上面幾個構面的分析,企業現在不是考慮要不要導入 AI Chat 工具,而是企業要怎麼導入?如何導入?
企業如何導入 ─ 從小範圍進行
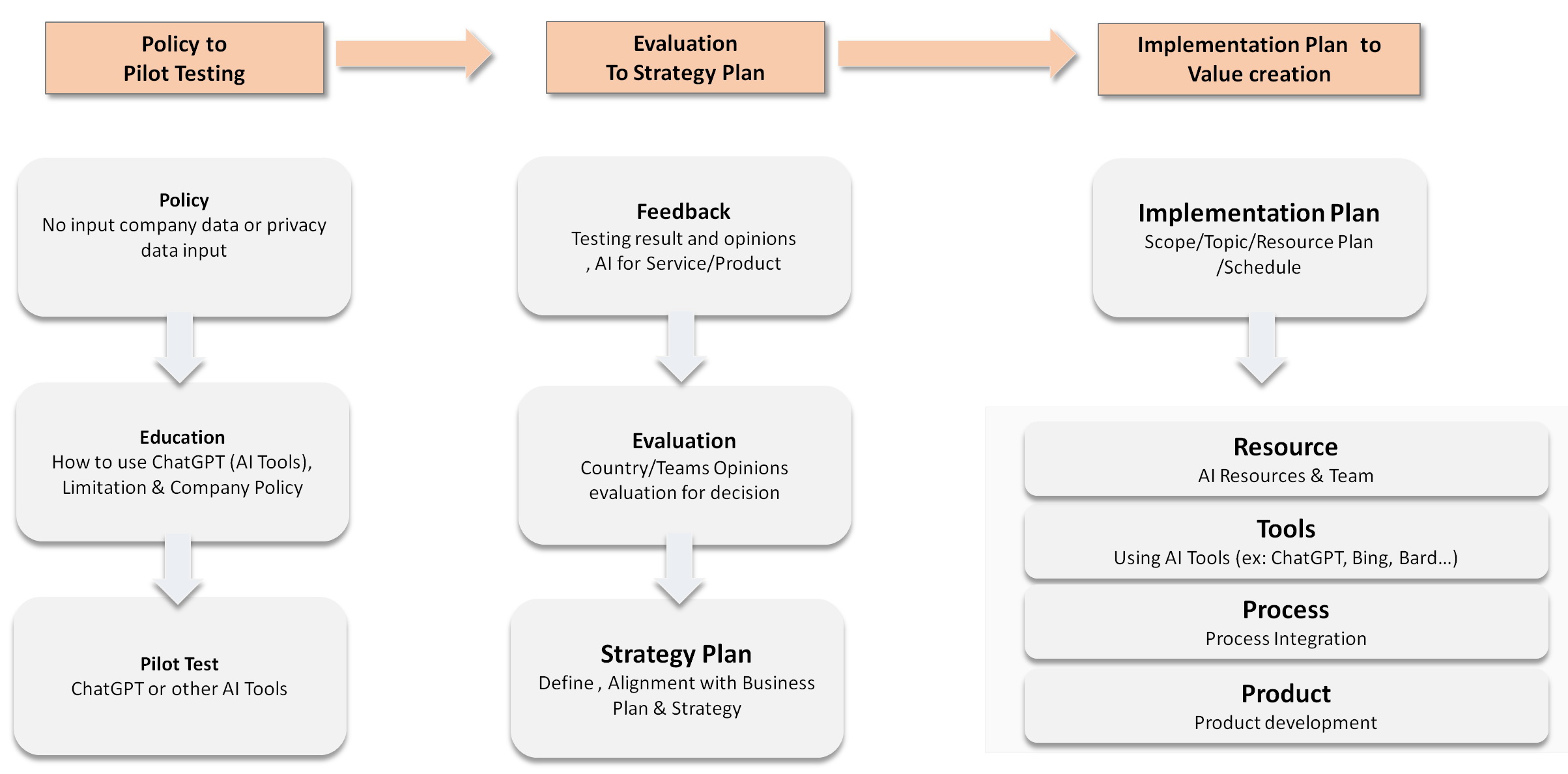
企業可以思考,針對 ChatGPT 或其他類似的 AI Tools 成立一個工作小組,從小範圍進行教育訓練、試點試做與評估,然後連接企業的策略(Business Plan),接著挑選最有價值的項目進行。同時,資源內外盤點與組建團隊也需要被考慮。
1. Policy to Pilot Testing:
企業可以先定義公司的政策(Policy),成立一個工作小組以及種子部隊,針對這些工作小組進行員工的教育訓練,並說明如何使用哪些行為是不行做的,開始熟悉這些工具,並試著設定一個小範圍的專案範圍,然後試著完成。
2. Evaluation to Strategy Plan:
根據這個小範圍為專案的執行收集回饋與意見,然後評估這些回饋的意見。這些意見中,有些是好的回饋,有些則是遇到了不好的經驗。無論好或壞,都是企業員工親身的體驗。接下來,企業各部門主管與這些專案小組的成員可以聚在一起進行腦力激盪的討論,並試著將 AI 連接 Business Strategy,訂出願景、規範以及策略目標與步驟。
3. Implement Plan to Value Creation:
下一階段為導入實作階段,如果企業已經有專責負責 AI 的團隊,這個團隊可以進行 Implementation Plan 去定義解決的問題、專案範圍/時程/資源、預算等。若企業目前還沒有專責單位,可以考慮成立一個專責 AI 的團隊開始接手企業未來 AI 的規劃、技術以及執行、維運。接著在各部門所需要的資源進行檢討,並評估&使用相關 AI 工具,針對內部跨部門的流程整合可否使用 AI 工具進行評估與執行,對外與客戶/供應商/夥伴的流程或系統,評估是否可以建置相關的 AI 服務;產品和 RD 團隊則可以評估 AI 與 AI 工具導入產品後是否可以創造額外或獨特的價值。
企業導入生成式 AI Chat 方式
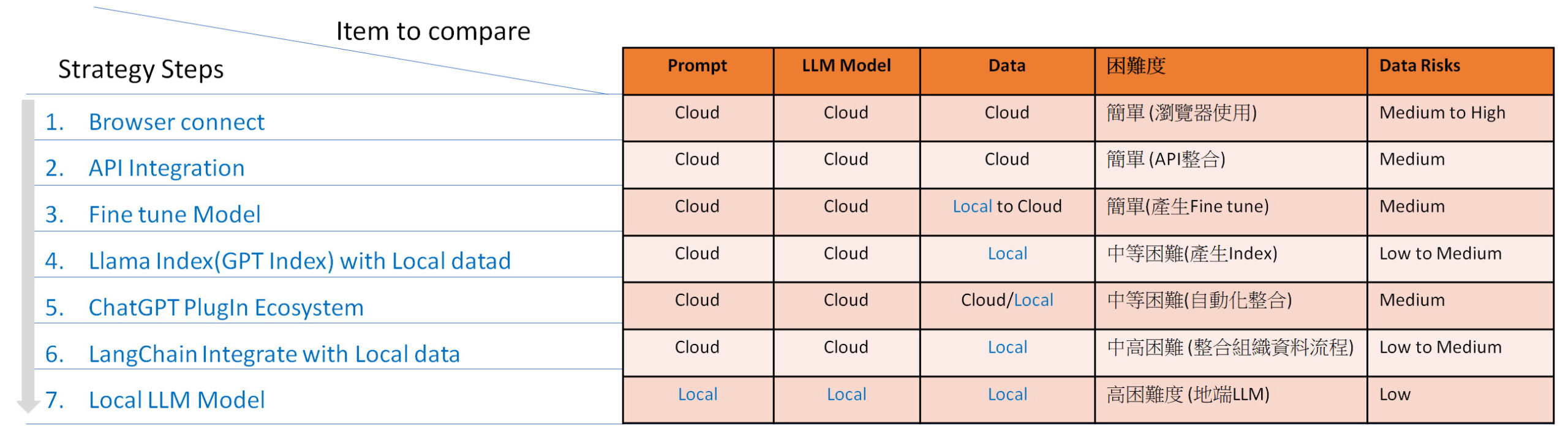
這一年相關 AI Chat 與大語言模型與工具發展迅速,筆者經過整理以及實作驗證,提供下面七種方式供讀者參考。這七種方式由簡單到困難,企業可以依照自己的策略與資源多寡,進行規劃與執行。
1. Browser connection:
透過瀏覽器連接到這些 AI 工具,無論是連接到 ChatGPT、New Bing、Bard 或 Claude 都是直接與簡單。在使用之前,企業最好訂好相對應的 Policy 以及做好員工教育訓練。甚至有企業針對員工連接這些 AI 工具,做了一個類似 Agent 代理服務。員工輸入的 Prompt 會透過這個 Agent 傳遞到這些 AI Tools,這樣的好處是,企業可以在 Agent 上留下 Log,一方面做為後續的分析;另一方面,也可以提醒員工不要輸入公司內部的資料。2023 年 11 月,OpenAI 在 DevDay 新的發布 GPT-4 Turbo,數據更新到 2023 年 4 月,並提供 128K 長度的輸入,也提供「多模態 AI」支援聽說讀寫,透過 Seed Parameter 重現一致性的輸出,並推出 Copyright Shield,客戶免受版權訴訟。
2. API Integration:
是目前這些重要的 AI LLM 業者的收費營運模式。由於 LLM 訓練與建立除了研發能量外,也需要有大量的訓練資料與算力,不是一般公司所能負擔。透過 API 的整合,政府、企業或組織可以開發所需的應用系統(Applications),透過 LLM 業者提供的 API,將自然語言文本產生推論,語音的識別或是圖形的產生等工作,由這些 LLM 業者來負責執行。而這些 API 的使用與整合,都提供的相關使用範例。使用起來困難度不高。
3. Fine tune Model:
將企業的資料,透過大語言模型提供的 Fine tune 模式,將企業的資料進行處理,並將 fine tune 的結果放置在雲端(假設為 devinci:ft-2023-04-17-05-22-42)。下次可以透過 API 去指定採用的 LLM 為 devinci:ft-2023-04-17-05-22-42,那執行參考的除了原先 LLM 預訓練的資料外,也因為有企業 Fine tune 的資料,產出的結果會比較有高品質的結果。此一方法,有完整的文件與範例,困難度不高。
4. Llama Index(GPT index) with Local data:
透過此一方法,除了可以降低拋轉到 openai 的 Token 數外(LLM 有上下文輸入的長度限制,另外 API 的費用和 token 資料量成正比),可以將企業的 Local data 先切割若干小的 chunks 並進行 embedding 處理(向量化處理)。當使用者輸入 Prompt 時,會先檢索向量化後的 index 取得高相關性的一個或多個 chunks,然後將 Prompt 與 chunk 合併為一個新的請求給 openai api,並取回執行後的結果。透過這樣的方法,企業的資料因為被預處理過,查詢出來的結果比較有效。使用起來困難度中等。
5. ChaGPT Plugin :
OpenAI 提供自己以及這些第三方服務,整合 ChatGPT 達到更豐富的服務。包括:Browsing、Expedia、Wolfram、VoxScript、Zapier…等。透過 Browsing 可以查詢即時網頁的內容;透過 Wolfram 可以處理數學計算能力與圖像呈現的能力;透過 Expedia 可以搜尋飯店、機票、旅遊資訊;透過 VoxScript 可以查詢 Youtube 影音資料;透過 Zapier 可以結合多種軟體/服務進行流程自動化處理。使用起來困難度中等。
6. LangChain integrate Local Data:
透過 LangChain,可以讓企業整合 SQL Database,讀取文件檔案(pdf、ppt等),串接不同的 LLM、Prompt 處理、Output Parser、Embedding、Vector Store、Indexing & Chain 等等功能。此一方式為中高困難度。
7. Local instance with Local LLM Model:
有些企業,考慮到網路連線以及資訊安全,希望建構自己專屬的環境,那麼則可以考慮採用此一方式 ─ 安裝已經開源的 LLM 模型在企業環境(這裡說的不是從頭重新訓練建構一套 LLM,一般企業比較不可能採用,OpenAI 提供的資料其單次訓練費用高達 1,200 萬美元)。這樣包括 Prompt、LLM 以及 Data 都在企業控管的環境內,安全性最高。但已經涉獵到大語言模型(LLM),相對需要投資的也最多,包括 LLM 模型、人才以及算力。連中研院這樣的研究單位,在 2023 年 10 月 6 日推出的大語言模型 CKIP 都生成出有爭議的結果,經過 4 天就下架,故此一方式非常有難度。(筆者實際安裝 LLM 在地端電腦上,並透過地端版 API 串接第三方的資訊系統 ─ 智慧助理系統,此一方式的困難度相對其他方式是也很高)。
結語
經過 2022~2023 的實證,AI 的發展只會越來越快,而生成式 AI 相關的服務也會越貼近終端使用者,無論是電腦、手機、瀏覽器、文書處理、搜尋引擎…等都已經或即將具備這些 AI 能力。故企業該思考瞭解這類工具、定義公司的 Policy、進行員工的教育訓練,然後透過小範圍的專案去熟悉這些工具,找出企業有哪些地方可以用這些工具去改善或創造價值。如:智慧助理、會議助理、AI 助教、智慧客服、自然語言(NLP)資料庫…等。
本文最後提出了幾種導入的方式供企業參考:
- 小型企業因為資源不夠,可以採取瀏覽器連接的方式進行;
- 中型企業則可以考慮 API 或是 Fine tune model/Llama Index(GPT Index)等方式,將企業內部的資料進行預處理,然後連接到企業內部的系統;
- 中大型企業則可以考慮 ChatGPT Plugin 進行流程 AI 與自動化,透過 LangChain 串接企業內部的文件資料庫(Word、PDF、Powerpoint…等),串接內外部流程與在產品上加值;
- 大型企業/超大型企業或集團,則可以考慮在企業內部建立 Local 大語言模型並串接 Local 的資料庫,甚至在進一步進行小數據的 Fine tune,產生更安全與獨特的策略目標。
(本文授權非營利轉載,請註明出處:CIO Taiwan)