Google 在最近,也就是 2024 年 4 月底,發表了其大型語言 Gemini 在臨床醫療上的新版本,稱之為 Med-Gemini,號稱取得了重大的進步與突破,同時在醫療應用的效能測試上,甚至優異於 OpenAI 的 ChatGPT4。本文針對其所發表的論文 Capabilities of Gemini Models in Medicine 中所提出的各項新發展加以討論,評估其對臨床醫療的效益。
文/潘得龍‧國立雲林科技大學資訊管理系專案助理教授
試想在醫院中工作的醫師,每天必須面對許多情況不同的病人,透過診斷以及各類檢查的協助,讓自己能夠儘量掌握病人的病情,能夠對病人有清楚的診斷溝通、正確的治療計劃,同時以同理心為基礎建立醫病之間的信任。病人的病情變化萬千,一瞬之間可能就會有很大的轉變,掌握病人的病情必須從電子病歷、不同的醫療影像、各種不同的醫事專科的檢查資料,和不同專科別的醫師所提供的資料。
醫療應用的 LLM:Med-Gemini
許多不同的專案都在嘗試應用大型語言模型(LLMs) 的人工智慧技術於臨床醫療上,如 Google 的 Gemini 和 OpenAI 的 GPT-4 等,不過由於回應的效率和可靠性,至今仍難以真正在臨床上應用。而 Google 所推出的 Med-Gemini 想要達到一個革命性的突破,本文檢視論文內容,對於其企圖做了審視與評估。
[ 熱門精選:得安全 AI 系統者 得天下 ]
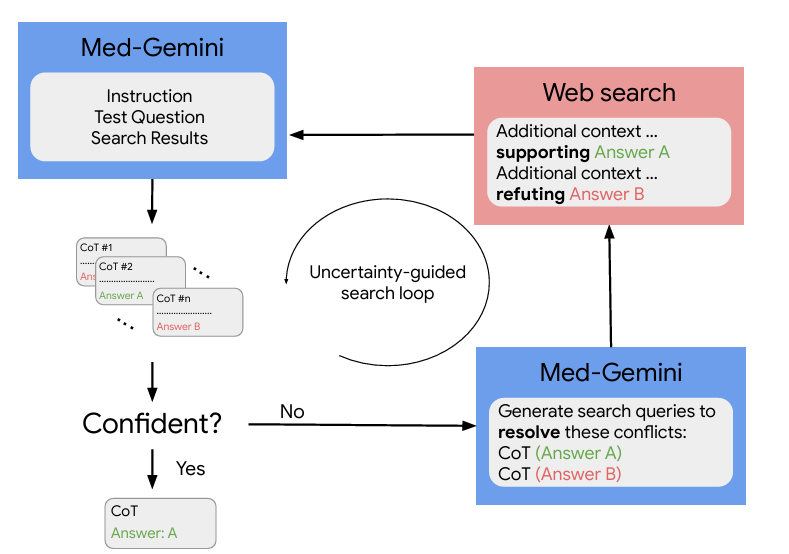
Med-Gemini 承襲自 Gemini 原來在語言和對話、能夠掌握多樣性資料,以及冗長文字內容推論等能力。針對新的醫療版本,Google 增加能夠搜尋網頁進行自我訓練,使用了不確定性導引搜尋策略。這兩樣技術的結合更能夠應付複雜的臨床醫療推論任務。其對長文字內容的處理,在對醫療診斷的應用更是重要。必須要能分析來自各種不同醫療資料來源的資料,像是電子病歷內容、查影像與錄影等。下列是 Med-Gemini 這次推出版本的重要特色功能:
一、Google Gemini 大型語言模型為基礎的臨床推理能力,能夠做到長文內容推論
之前必須做到病人資料的掌握,能夠掌握病人的過去病史,不同時間點的病情以及最新的的病情進程、檢驗數據,之前治療的效果,然後搭配各類流行病學作為背景思考資料。不同的思維使用了 CoTs 思想鏈結技術,持續進行思考以及後續的搜尋。Google 在論文中指出,設計了一種全新的不確定性指引以及循環搜尋流程,會先產生多個不同思考路徑,然後才產生搜尋提示,而且處理的內容不限文字。病人的資料
二、設計了編碼方式,能處理多資料來源
從基本的電子病歷資料,到各類醫學影像以及像是心電圖波形資料等。具備 zeor-show 能力(AI 的一個特質,做到人類人眼看到圖片立即能領會的能力)。此外,藉由所開發的醫療裝置編碼器,能夠整合各種醫療信號,甚至能夠加入裝待裝置,有利於長期追蹤病人的心跳、活動、地理資訊,營養飲食資料以及其它的環境因素等(例如空氣品質)。
外科類的手術紀錄通常會以影片的方式呈現,而這個系統則是應用了 AI 的物件偵測技術,影像語意分割(semantic segmention)、物件追蹤、動作分類,因此能夠做到開刀階段的確認,工具偵測與追蹤,甚至能夠做到手術技術評估。搭配前面所提到的長文推論能力,而能做到會資訊內容豐富的影片資料的理解。
三、藉由外部網頁資料搜尋進行自我訓練,進行高階的推論,也因此能夠做到病歷摘要、撰寫醫師轉介信等(圖 1)
能力測試
使用了 14 種醫療評量系統進行測試,內容包含了文字推理、不同資料來源以及長文處理的工作等,針對 ModQA(USMLE) 進行 SoTA 測試可以達到 91.1% 準確率。實際使用環境測試,可以擔負轉介信撰寫以及病歷摘要等。
[ 加入 CIO Taiwan 官方 LINE 與 Facebook ,與全球 CIO 同步獲取精華見解 ]
在針對長影像以及病人的病歷內容,進行了長文推論的測試。其中病人的資料包含了超過 100 篇以上的病歷紀錄,這些病歷紀錄並不是結構化的資料,病人的記錄字數從 20 萬字到 70 萬字不等。在影像部分則是提供了像是腹腔鏡膽囊切除術,然後要求系統找到某個關鍵步驟。圖 2 顯示了在對系統加入了自我訓練以及搜尋等步驟之後,回答的準確率逐步的提升。

論文中也展示了實際應用的案例,像是提供一個皮膚病的圖片,系統在詢問病人一些問題之後,做出了正確的診斷以及治療建議(圖 3)。另外一個案例是分析胸部 X 光片,識別退化性椎間盤疾病,討論因果關係和相關性之間的區別,以及有背痛病史的患者,建議進一步的檢查以確定背痛的原因,並使用非技術性語言提供報告,以促進患者理解和溝通。這些案例的呈現,令人印象深刻。

Med-Gemini 新模型令人興奮的前瞻性應用
在 Open AI 不斷推出新的 AI 模型刺激下,Google 也在這個領域不斷地推陳出新。從前面的介紹,模型的能力可以在外科護理中具備發展潛力,像是在複雜手術過程中以及即時的方式協助外科醫生或是學習的醫師,以提高準確性和開刀品質。
[ 熱門精選:生成式 AI 企業應用與導入現況 ]
其長文分析能力,能夠有效解析大量病歷資料,並將其綜合成清晰、簡潔的病歷摘要。使用者可以使用自然語言詢問特定病情,像是肺炎或相關的診斷結果,經過簡化對長篇醫療資料的分析之後以對話介面的方式呈現,這項功能可以有效地減輕醫師和病人的認知負擔。
不過老問題仍然存在,大型語言 AI 模型仍有極大出錯的可能性,在應用於實際臨床醫療時,AI 技術仍然只能扮演著輔助的一環,還是需要人類專業醫療人員的再次確認。同時,在論文中,以相當大的篇幅探討了語言模型的偏差問題,這牽涉到複雜的人類文化與環境的差異,甚至人類使用時的惡意介入,就還需要持續投入解決了。
參考文獻:
Saab, K., Tu, T., Weng, W.-H., Tanno, R., Stutz, D., Wulczyn, E., Zhang, F., Strother, T., Park, C., & Vedadi, E.(2024). Capabilities of gemini models in medicine. arXiv preprint arXiv:2404.18416.(本文授權非營利轉載,請註明出處:CIO Taiwan)