
口述/孫培然‧彙整/CIO編輯室

過去三年的疫情蔓延,讓很多觀念必須要改變。本來是希望可以清零,但是發現清零很難,所以我們只能跟病毒共存。資訊系統也是一樣,要確保零故障,那是不可能的事情,所以是要能夠容錯,也就是說一旦某個服務出問題,其他服務還可以持續運作,要怎麼做到減少問題,避免互相感染。
我們要怎麼強化系統的韌性,讓它不可以當機。我們必須要思考,未來應該怎麼做比較好。
打破傳統思維重新設計 HIS 資料庫
我的第一個建議是,打破傳統思維重新設計 HIS 資料庫。以前在單體的時代,可能是很多服務共用一個資料庫,但在微服務架構下,期望的是一個服務一個資料庫。好處是可以很快速的去轉移資料,不會互相牽絆耦合,可以確保整個獨立性,不會互相干擾,這是未來系統架構的趨勢。
但傳統式的資料庫需要重構嗎?微服務架構未來的瓶頸,可能會是在集中式的資料庫,要如何來化解呢?既然程式都重構好了,難道資料庫也要比照辦理嗎?這是一個值得反思的議題。
[ 推薦閱讀:疫情三年企業轉型加速 企業IT邁向現代化 ]
從微服務架構來講,資料庫是最後一哩路,那可以「微資料庫化」嗎?
這個問題的根源,是關聯式資料庫管理系統(RDBMS)太過於依賴「關聯」及「交易」的處理,也必須經常用到 Join/View/Transaction,所以有很多的問題必須要去克服,比如說 Table 如果太大,可能要切割成不同的 Table。比如說把門診跟住院的資料庫,切割在不同的資料庫,以減少資料量的產生,提升整體效率,這種做法也稱為「垂直分割」。
假如門診資料超過十年以上,資料量會很大,此時就需要進行「水平切割」,如將近三年的資料,放在線上的資料庫,把三年之前的舊資料,則是放在冷資料庫(Cold Database)上。透過降低資料量的筆數,提升整體效率,以及一旦資料庫有問題時,可以縮短復原(Recovery)的時間。
要如何執行跨越服務之間的 Join,也是一大問題。多租戶設計,多個使用者的資料庫的實體隔離,在在顯示我們要怎麼去應付這些傳統式資料庫的一些議題。
關聯式資料庫的瓶頸跟問題
現行關聯式資料庫的瓶頸跟問題,第一是過多的 Join 導致整個效能的低落;第二是高頻率的讀/寫,如數千萬筆的讀/寫資料,會影響資料的效能。第三是資料結構的異動很難,每異動一個資料結構,就必須要去停機維護。就算我們不想這麼做,但是不停機維護,就沒辦法去做資料結構的異動。第四是怎麼降低 DBA 的維護成本跟門檻;第五是敏捷開發,快速反覆運算要怎麼應付;第六是巨量資料的查詢,一查就是數百萬筆的資料,要怎麼去處理;第七是非結構化資料的儲存應用,比如說地理地圖,在關聯式資料庫可能永遠都做不到;第八是如何通過快速部署,或者線上的水平擴展,這也是傳統資料庫沒辦法做到的問題。最後是跨平台部署,也就是如何自由的在地端與雲端移轉。這些都是厚重的集中式關聯式資料庫所存在的問題。
所以我一直在鼓吹 HIS 資料庫改用 NoSQL 資料庫來替換關聯式資料庫,但到目前為止,台灣沒有一家醫院的主管敢這樣做。因此我希望能從另外一個角度,來改變關聯式資料庫的設計模式。
比如說,我們要開發一個門診醫囑資料庫,先是要做需求訪談,針對每一個門診的看診記錄,包括記錄看診號碼、病歷號碼、姓名以及性別等。還有醫師當次所開出的醫囑相關資料,包括醫令代碼、醫令名稱、類別…等。經過訪談過後,我們會通過系統分析師,把資料正規化,也就是把資料拆解成不同的 Table Schema。
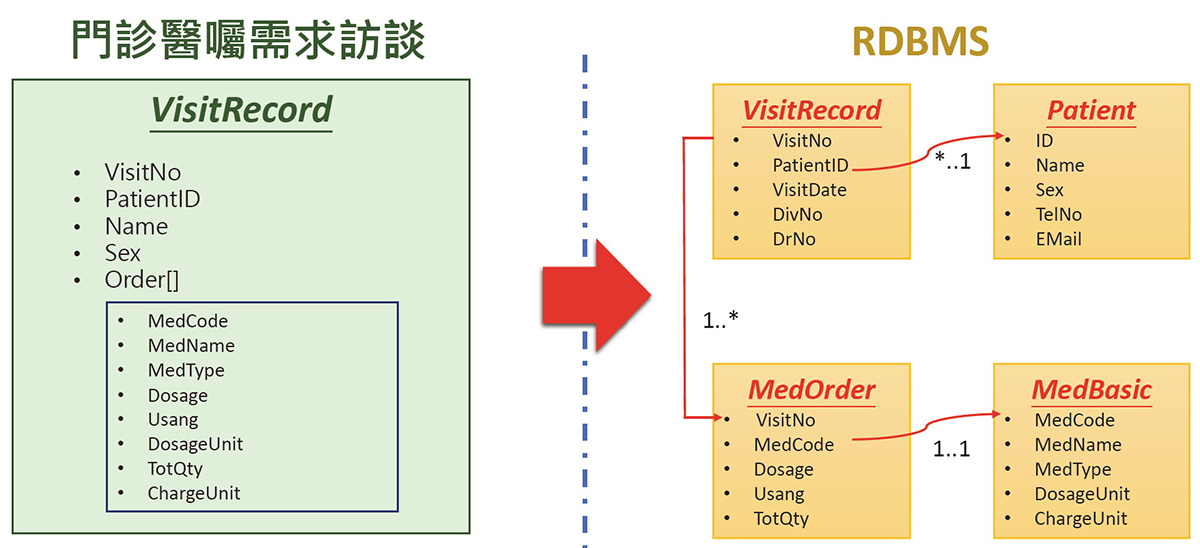
如圖一的訪談記錄,就會拆成四個 Table。第一個就是病人的基本資料檔(Patient),病歷號碼、姓名、性別等。每一個病人看診一次,就會有一個看診記錄檔(VisitRecord),包含有看診號碼、病例號碼、看診日期、科別、醫師等。每一次看診醫師開立處方就會有一個「MedOrder」也就是醫囑處方檔,裡面會有很多筆的檢驗檢查或藥品的資料,這些檢驗檢查及藥品都會有專用代碼,會關聯到醫令基本檔(MedBasic),也就是這個藥品或檢驗檢查的基本資料的參考檔。所以原本的一個文件,會透過關聯式資料庫就會展開成四個 Table 去 Join 它,這是在需求訪談以後,正規化成關聯式資料庫所產生的架構。
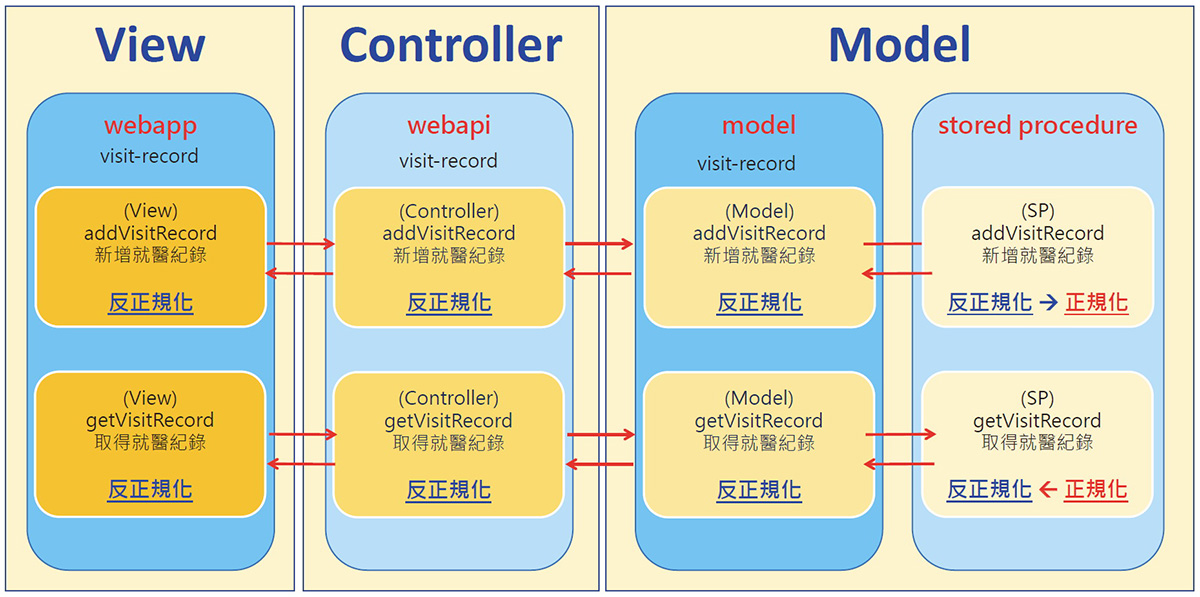
在談關聯式資料庫正規化產生的問題之前,我們要先了解 MVC 的軟體架構。MVC 的架構分為 Model(邏輯層)、View(表現層)及 Controller(事件層),主要的 Model 就是跟關連式資料庫去串聯。從 Model 到 Controller 到 View,很多資料就會透過 MVC 的架構,拆解成資料流。
如新增一個就醫記錄時,這個就醫記錄就會反正規化,轉到 WebAPI,也就是 Controller,再把它拋到 Model,Model 就會將完整的資料拆解成四個 Table,分別存到資料庫裡面,這就是資料庫的正規化的方式。如果要把資料取回來,再去 Join 這四個 Table 變成反正規化,再拋轉到 Model、Controller,再到 View。
在這樣的過程當中,我們看到有這麼多的步驟,但其實大部分的資料都是反正規化的資料,此時就需要把反正規化變成正規化。從資料庫取出的資料,要先把它做 Join,完了以後變成反正規化,再轉到 Model、Controller 到 View,如圖二所示,繁複的正規化與反正規化。
關聯式資料庫的問題
所以我們花了很多時間去做正規化及反正規化,但其實真正在用正規化資料的時機卻不多,因為關聯式資料庫要做正規化,是為了減少資料庫的冗餘以及確保資料的一致性。
但是做了正規化以後,會產生許多問題。第一個是關聯查詢,會讓效能變差。本來一筆資料只要一個 Table 取得就可以出來了,但現在卻要關聯四個 Table,資料就可能不止一筆,造成效能變差。
第二個是可讀性不夠好,因為需求轉變成正規化,資料可能會不夠實用,必須要正規化,才有辦法可讀。除此之外,本來一筆資料現在變成四個 Table,就不止一筆資料,就要去做 Transaction 才能達到 ACID 的概念。
所以我們開始反思,關聯式資料庫管理系統是在 1970 年前所設計的產物,那個時候的記憶體(Memory)是用幾 KB,儲存體(Storage)是用幾 MB 來計算,也就是說那個時候的記憶體跟儲存體都非常昂貴,資源也非常的少。所以當時只能用「時間」來換取「空間」,也就是儘量減少資料的冗餘,來換取更大的空間。
但現在的伺服器記憶體都是算幾 TB,儲存體都是算幾 PB。而我們現在重視的是效能,希望快速的存取,所以我們現在應該是要以「空間」來換取「時間」。也就是讓常使用的資料存取放在一起,所以遵循高內聚力、低耦合力的概念,就是現代化資料庫設計的概念。
也就是說,在大多數的情況,應該是優先使用嵌入(Embedded),而不要再去 Join。好處是可以快速的存取,經常在一起使用的資料,就是最適合的,減少整個查詢的 Join,就可以提升效率。
[ 推薦閱讀:孫培然專欄所有文章 ]
但有一點要注意的是,一旦在一起的資料如果大到 16 Mb 以上,就盡量不要在一起,而是盡量把它分開,需要的時候再把它 Join 回來就好了。不然資料如果太大,記憶體耗用當然就會越多。
什麼時候應該用關聯(Relational)?如果這個資料只提供單獨存取,就可以保持 Relational,或是參考 Schema Design Patterns,哪些資料應該在一起或是做關聯。最好盡量 Embed,除非資料是成千上百,或是資料單獨異動非常頻繁,那就儘量使用 Relational。再來就是存放的資料會隨著時間而爆炸性成長的,也要把它分開
最大的原則,就是能 Embed 就直接 Embed,不行的時候再用 Relational。
正規化所出來的 Table,一般通常要 Join 到 4 個 Table 以上,但如果用非正規方式,就不需要做 Join,只有一筆資料就存取了。所以如果你不做任何關聯式資料庫,效能可以提升兩倍以上。目前已有超過 90% 的網站及應用程式,都是使用 NoSQL 的 JSON 格式來做資料交換,所以未來資料庫的結構,可以慢慢的朝向以 JSON 的方式來呈現。
現代化的資料結構設計
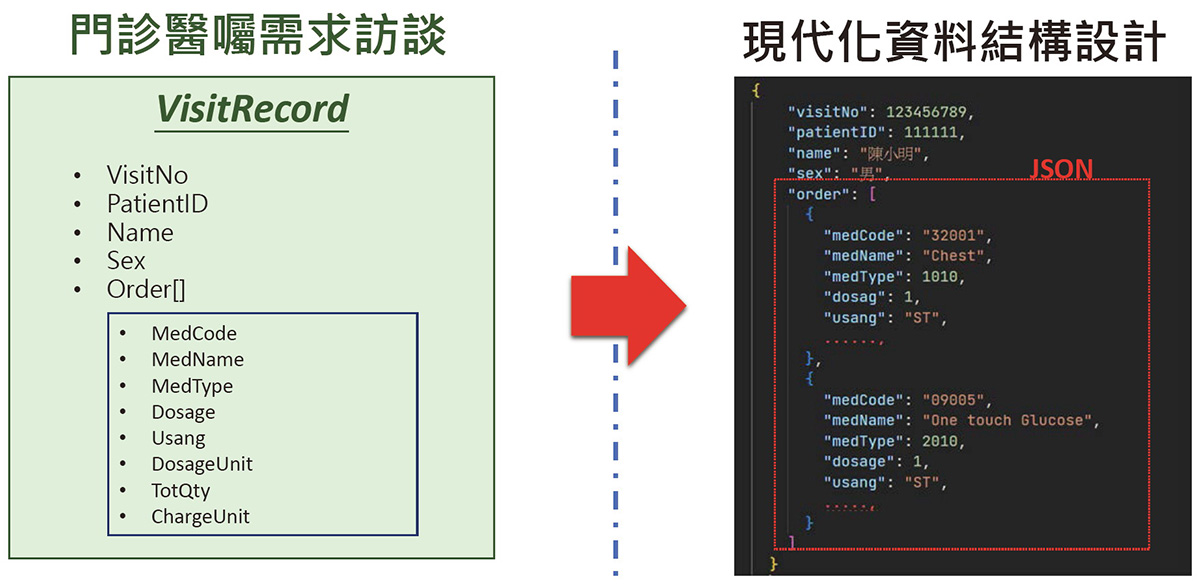
如果以現代化的設計方式來看,我們可以很真實的反映整個門診醫囑的資料情境,不需要去做正規化,就可以將訪談資料完完整整的存成 NoSQL 的 JSON 格式。(圖三)
舉一個很簡單的例子,以傳統方式來設計「出院病歷摘要」的資料結構,我們通常會設計兩個 Table,一個叫做主檔(Master),一個叫做明細檔(Detail)。主檔的資料就會存就醫號碼、報告人員等,這是屬於主檔的資料,它會關聯到一個明細檔,明細檔就是記錄出院病歷摘要的每一個細項的內容。
假設出院病歷摘要裡面有 15 個項目,就會有 15 筆資料去記錄每一個項目,比如說(1)代表住院診斷,(2)代表出院診斷,(3)代表主訴…等等,這些東西以號碼來編,去記錄它每一個項目的內容。用這樣的方式,資料就會用到兩個 Table,也就是主檔資料 1 筆,明細檔的資料為 15 筆。
如果是這樣的資料結構,未來我們要新增異動資料的時候,就必須要做 Transaction。因為資料是跨兩個 Table 有 16 筆資料,所以必須要做到 ACID。存取的時候,一樣要把這兩個 Table Join 起來,再反正規化打包成一筆回傳回來。
如果用現代化的資料結構來設計,同樣是出院病歷摘要,如圖四只要一個 Table 就可以了。Table 裡面一樣記錄就醫號碼、報告人員。比較特別的是,文本就把它存成 JSON 的格式,再把出院病歷摘要的 15 個項目,直接打包成 JSON 的格式,不但可以確保資料一致性,而且可以只取得一筆資料,不用跨 Table,所以根本不需要 Transaction,在存取資料的時候,根本就不要 Join。
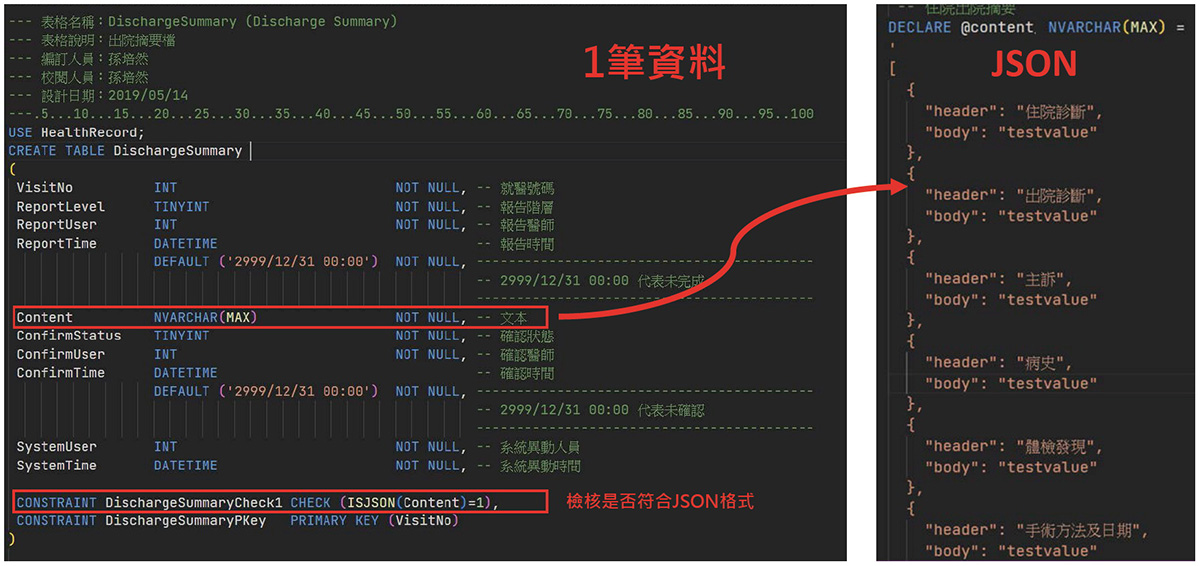
在 SQL Server 2016 以上版本,就有支援 JSON 的格式相關應用及檢核功能,如果不符合 JSON 格式,也不會讓你存進去。也就是說,未來的資料庫結構,除了會提供查詢資料要獨立設置一個欄位之外,其他很多相關的內容都可以把它打包成 JSON 格式,如圖四所示。。
使用 Stored Procedure 的價值
也許你曾聽說,未來如果要更換其他的資料庫,最好不要用 Stored Procedure,也不要用 Trigger,不然很難更換資料庫管理系統,但其實這是一個迷思,這個迷思已經害了我二十幾年。
反思一下,SQL 標準嗎?不標準嗎?SQL 號稱標準,但只有 70%~80% 的標準,還有 20% 根本沒有標準。所以今天不管你是用 Oracle、SQL Server、PostgreSQL、DB2、MySQL、Informix…等,只要你用了某一個資料庫的 SQL 語法,未來你要換任何一個資料庫,你都必須要去改寫後端成千上百支的後端程式。
所以未來更換資料庫的正途,就是你要善用 Stored Procedure,善用 Trigger,還有讓後端只能呼叫 Stored Procedure。在更換資料庫的時候,就不需要去更改前後端的程式,只要把 Informix 的 Stored Procedure,改寫為 SQL Server 的 Stored Procedure,就可以很順利的更換掉資料庫,後端程式完全不用改。因為後端所呼叫的就是一個 Stored Procedure Name 而已,中間通過 JSON 來做傳輸,根本不需要改。如果今天又要把地端的 SQL Server 改成雲端的 Azure SQL,一樣直接把 SQL Server 的 Stored Procedure,改寫成 Azure SQL,就可以完成改換資料庫。
[ 加入 CIO Taiwan 官方 LINE 與 Facebook ,與全球 CIO 同步獲取精華見解 ]
如果使用 Stored Procedure 的方式,完全取代原始的 SQL 語法;使用參數化的查詢,而非動態式的組合查詢;把輸入跟輸出的參數都打包成 JSON 格式來傳輸,讓前端的程式不能跟資料庫溝通,必須透過後端的程式,後端的程式只能呼叫 Stored Procedure,不能使用 INSERT、UPDATE、DELETE 及 SELECT 等語法。
如此一來,就可以跟 SQL Injection 攻擊說再見,根本不會資安的議題。除此之外,我們可以控制程式設計師在資料庫的存取許可權,只有呼叫 Stored Procedure 的功能,他不能擁有 INSERT、UPDATE、DELETE 跟 SELECT 的語法,可以真正的確保資料安全性。如果你是用原始的 SQL 語法寫在後端的程式碼中,你很難去控制不讓程式設計師有資料庫的 INSERT、UPDATE、DELETE 等的許可權。所以整體而言,使用 Stored Procedure,不管是在效能,未來的期待性、更換性以及安全性,都非常的重要。
(本文授權非營利轉載,請註明出處:CIO Taiwan)











