
有人常常在談,用NoSQL根本沒有事務性交易(Transaction),也就是沒有像關聯式資料庫有ACID的特性,讓資料儲存保持完整性及單元性的概念。其實談到ACID,就要談到CAP的理論,也就是要確保資料的一致性,並不一定要在一瞬間有一致性,也就算是沒有一秒兩秒的一致性,一樣可以達到整體一致性的概念。其實我們現在各行各業的有很多資料都放在雲端,如果真的要做到ACID,坦白講,網路品質也是值得商榷的。
[ 下載 2020-21 CIO大調查報告,掌握2021年企業IT導入趨勢 ]
所以要談ACID或是CAP的概念,就要牽涉到整個資料庫日後的設計理念跟概念。如果說採用NoSQL資料庫後,卻還是用關聯式資料庫的設計概念,那一定會有很多的交易產生,也就是在新增或更新很多表格時,只要有一個失敗就要重新還原(Rollback)。
但如果以一個文檔(Document)的設計方式,所有的關聯就沒有了,文檔儲存成功就成功,失敗就失敗,就不會發生儲存多筆資料時,中間只要有一個失敗還要重新還原回去的狀況。
如何從SQL轉換為NoSQL
我們要怎麼從SQL轉換到NoSQL?以關聯式資料庫管理系統(RDBMS)轉換NoSQL的MongoDB為例。在圖一中是兩者結構的對照。左邊是關聯式資料庫,最高等就是Database。再來就是Table,每一筆資料都叫Row。因為Table要加快速度,就會有一個Index,若要JOIN什麼資料就透過Index的互相JOIN,另外,新增、刪除及修改就會用到Transaction。

對應到MongoDB,有一些名詞就會改變,Database還是Database,但是Table就改稱為Collection。每一筆資料稱為Document。兩者都有Index,但以NoSQL而言,建議儘量少用關聯資料方式,因為關聯會產生很多複雜性,還要JOIN很多Table,所以NoSQL會儘量將很多的資料變成一個文檔。
所以關聯式資料庫轉換MongoDB時,模型設計兩種方式,最常用的是以Embedded方式,將資料嵌進去文檔裡面,若Embedded進去的資料太大,則不建議Embedded進去,才改用References關聯,就跟傳統資料庫的JOIN是一樣的。其設計原則就是,若資料關聯性是一對一就直接用Embedded的方式,如果是一對多,資料量不大就可以用Embedded,資料量很大就用References,如果是多對多,可能就要個案討論。另外,早期NoSQL被詬病的地方,就是沒有Transaction,但MongoDB在4.0以後就已經有ACID的概念。最後值得大家深思的是資料的存取頻率,是存檔次數較頻繁?還是取出來查看次數較為頻繁?
[CIO都在讀: AI最常見的應用有哪些? ]
[CIO都在讀: 10個數位轉型成功案例 ]
[CIO都在讀: 所有企業都想要的12種CIO技能 ]
模型轉換:以病人看診資料為例
要從SQL轉到NoSQL,要先看整個模型的轉換。關聯式資料庫的正規化,主要是希望減少資料庫中的資料冗餘,增進資料的一致性。但正規化以後就會產生一些問題,就是上一期講的正規化以後,要反正規化,整個效能就會變得很差,可讀性也會變得很差,事務性交易也會變得更複雜,做得不好還會有 Table Lock 的情形發生。
解決前述問題的方法其實很簡單,以真實的狀況來講,「使用在一起的資料,就應該要存取在一起」,變成一個文檔。早期要把這些資料分開,是為了要節省空間,以圖二的病人的看診資料為例,首先會有病人的基本資料,然後會有這個病人到醫院來看診的紀錄及很多的病歷及醫囑資料,在關聯式資料表就需要有7個表格來互相關聯,如圖中Patient為病人基本資料表、VisitRecord為就醫紀錄表、SOARecord為病人主訴及評估表、DiagRecord、DiagBasic則為疾病診斷紀錄及名稱表、MedOrder則示記錄醫師開立醫囑資料表、以及關聯醫令代碼的醫令基本資料表MedBasic。
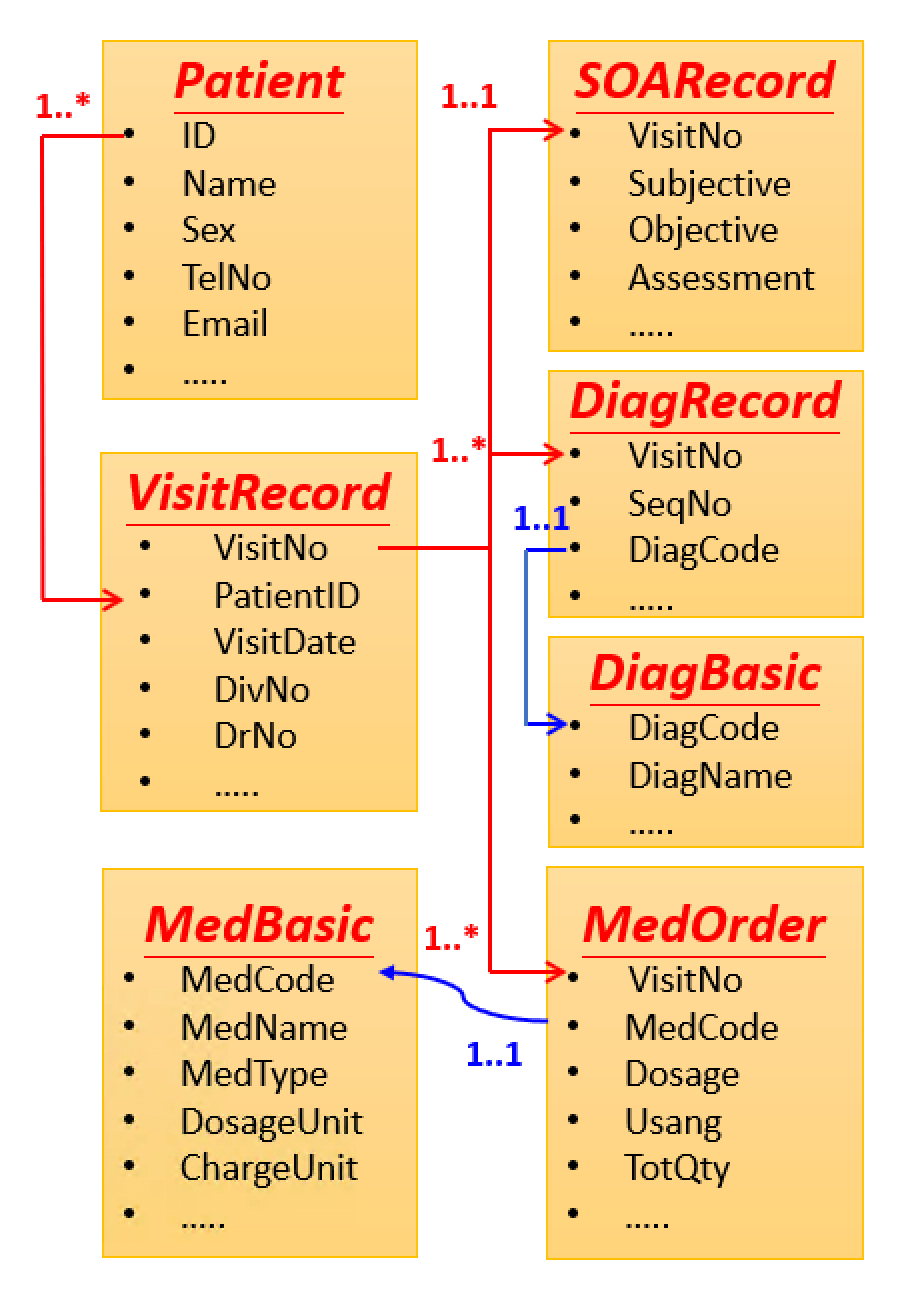
以MongoDB來講,如圖三所示,就是把一個病人的看診資料,包成一個文檔,我們只要抓到這個病人看診資料的文檔,就可以知道他有多少看診資料,就不必用去關聯其他的表格。這個就是Embedded的概念,在開發上非常的直覺方便,就不用JOIN。

可以再根據病人每一次的看診記錄,去查看醫師開立了那些醫令,一目瞭然的從一個文檔中,了解整個看診病歷資料,不必像關聯式資料庫像一樣還要 JOIN 7個表格才有辦法找到病人的看診病歷資料。
日後如果是要從關聯式資料庫轉成MongoDB,轉換時要思考那些是要用Embedded,那些是要用References。比如說我們有一個看診資料的文檔,記錄哪一個病人什麼時候來看診、是什麼原因及疾病來看診的,以及醫師開立了哪些醫令。而為了減少References,就直接Embedded進來,也不需要再去做JOIN,除非不適合用Embedded方式,才透過References的方式去完成資料的獨立模式。
模型設計:嵌入式或參考關聯
什麼時候應該用嵌入式(Embedded)?什麼時候應該用參考關聯(References)?以NoSQL資料庫而言,我們應該先思考,能夠儘量不做JOIN,就儘量要不做JOIN,建議是如果能夠Embedded,就儘量用Embedded,因為這樣就不需要去再作關聯了,所以在查詢速度一定會很快,尤其是經常在存取的資料,在存取時應該要做Embedded,可以減少查詢時的JOIN動作。
[ 加入 CIO Taiwan 官方LINE,與全球CIO同步獲取精華見解 ]
但文檔越大,記憶體就用得越多,所以文檔有一個限制,就是一筆文檔不能超過16Mb,如果資料會超過16Mb,會建議用References。或是這筆資料不會常常跟其他資料產生關聯,只是提供單獨存取,就會建議用References。
也就是說,單獨的資料異動很頻繁,就應該做References,不然每次存取一個大的資料,但可能只是異動某一個欄位而已。如果存放的資料會隨著時間出現爆發性的成長,也不建議用Embedded,因為一樣會有超過16Mb的限制。
在索引轉換方面,NoSQL的Index跟關聯式資料庫是很相似的。只是NoSQL有個好處,就是不一定要把它正規化以後,才可以做索引,除了內嵌式的索引,也可以在陣列式裡面去定義索引。NoSQL還有一個好處是關聯式資料庫沒有的TTL索引時效性功能,比如說可能有段時間如從2020年~2050年會很頻繁的存取某些資料,一旦超過這個時間,就不再將這個資料當索引時,就可以去指定文檔索引過期時間。
再就是它也有像關聯式資料庫,把很多欄位複合性索引,也可以做雜湊索引(Hash Index),用某個欄位的Hash值來建立索引。NoSQL也有提供一個屬於關聯式資料庫沒有的功能,就是稀疏性/部分索引/矩陣/地理空間相關的索引。
(口述/孫培然 彙整/CIO編輯室)
- [ 以NoSQL重構HIS資料庫(上) ]
- [ 以NoSQL重構HIS資料庫(下) ]
















