
口述/孫培然‧彙整/CIO編輯室

想要透過資料網格(Data Mesh)來加速數位轉型,首先要注意的是數位轉型的資料和資料需求。第一個要點是資料的賦能,分析巨量資料來達成應用增值 AI 相關應用,並能進行資訊分發調度及管理稽核,打造出一個資料交換機制。
第二個要點是大量資料的查詢需求,讓大量使用者可以瀏覽或操作,以及高併發資料的查詢,讓這些需求可以透過分散式架構,快速做到讀寫分離或者分配等,並具備高擴展性,隨時可增加資料庫數量,不須建置複雜的資料庫叢集。
第三個要點是新舊系統資料要做到即時同步整合,又不能損及舊系統資料庫的效能,並且可以執行高速的跨系統資料關聯查詢,當資料源有異動時,也才能自動更新目的端資料庫。
最後一個重點是分散式架構的資料備份和跨容器的備援機制,跨叢集的資料同步,以及應用層的資料一致性。這些要點都是數位轉型的相關需求。
我們能不能把微服務架構的好處,應用到資料跟事件驅動,創建出一種資料網格呢?也就是說,我們既然已經將線上交易處理(Online transaction processing,OLTP)系統都微服務了,也要試著慢慢的將更為龐大的線上分析處理(Online analytical processing,OLAP)單體式的系統微服務化,或許就可以打通之前產生的瓶頸和問題。
HIS 優化再造的工法
HIS 的優化再造,如果要做到無縫接軌,工程會非常浩大,就好像橫跨在火車鐵軌或是高速公路上蓋一座橋時,不能說在蓋橋時讓鐵路或高速公路全部停止行駛,而是要在可以行駛的時候,還可以繼續的去蓋橋。
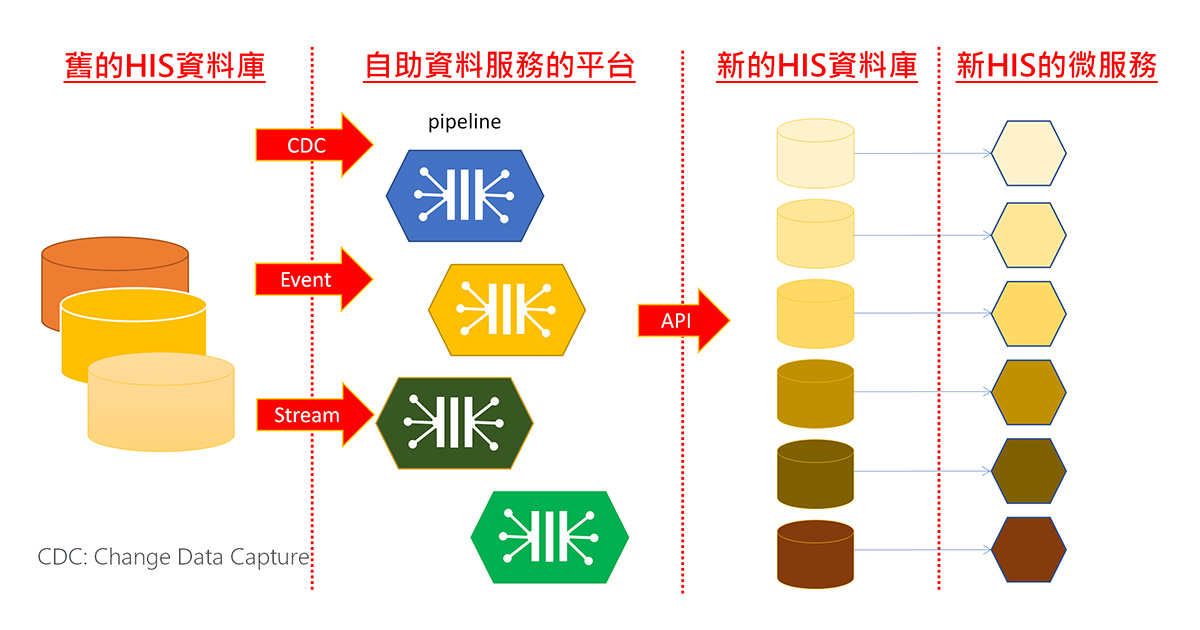
要如何讓新舊 HIS 資料庫能夠做到即時同步?如圖一所示,可以透過 CDC(Change Data Capture)、事件驅動(Event driven )或是串流(Stream),把舊的 HIS 資料庫,透過 CDC 匯入到自助資料服務的平台,以 Low-code/No-code 來設定資料轉置的方法,產生不同新資料的管線(pipeline),透過 API 輸出跟新資料庫去同步,一旦資料進來了,就可以即時通知,讓新舊資料庫做到即時同步。重新改寫的 HIS 微服務再去存取新的資料,新的系統只會針對新的資料結構去做存儲,不會跟舊系統有任何掛勾。
所以 HIS 優化再造的工法,可以借鏡都市更新計畫工程,每一個舊系統的更新就好像要改建老舊社區時,應該是先把未來的新 HIS 資料結構架起來,然後透過「資料即產品」的概念,讓舊系統的資料可以即時同步,接到新的HIS架構之後,完成整個資料的同步行為。
[ 2023年企業IT投資重點為何?資安、人才、ESG如何部署?下載 CIO大調查報告 立即揭曉! ]
如此一來,如果資訊人力多的時候,就可以做到地下樓層跟地上樓層同時作業,如果資訊人力不足,就可以先針對比較有問題的先蓋。也就是說新舊系統的同步,如果可以透過資料網格做到即時同步,若是這樣 HIS 還需要做到一次到位的更換嗎?這是值得大家思考的方向。
一旦做到資料同步以後,就可以開始一個一個抽離錯綜複雜的單體程式,慢慢的去建構新的 HIS 系統的微服務功能,不斷地迭代做到循序漸進的轉移。如果沒有很大的資源,或是人力不足時,就可以用前述的方式慢慢的轉移舊系統,先針關鍵性或較有問題的系統進行汰舊換新。
臨床研究數據中台
很多醫院會把他們的 HIS 的資料庫 ETL(Extract-Transform-Load;擷取、轉換和載入)到大數據中心的資料倉儲,但對於各科臨床研究中心的資料庫,如中風、外傷、胸痛、腎臟等資料庫,卻會碰到很多問題,原因在於管理大數據中心的人員,往往缺乏各專科領域知識,也就是不懂各專科的需求,且各科臨床研究中心的醫學領域太深奧了。
[ 加入 CIO Taiwan 官方 LINE 與 Facebook ,與全球 CIO 同步獲取精華見解 ]
因此,若能透過資料網格的聯合計算治理概念,下放資料所有權給不同的科別團隊去做資料治理,透過自助資料服務基礎建設平台,進行自助資料服務以 Low-code/No-code 來設定資料轉置的方法,產生不同新資料的管線。提供視覺化平台工具,讓使用者不用撰寫程式直接拖拉過來設定資料管線,如資料轉移或是設定不同的架構量子,中間可以透過資料的輸入及輸出互相溝通,這些資料的輸入跟輸出,透過 API 的方式來做溝通交互,讓各科的資料也就可以互相分享。各科的資料來源,不管是 Oracle、Informix、SQL Server 或 MySQL 都不用擔心,除了前述的 CDC、Event driven及 Stream,還可以透過批次轉檔機制,將資料輸出到自助資料服務平台,提供不同的元件讓使用者自己去設定及轉換,再提供給各個數據中台如神內的中台、腎臟的中台。
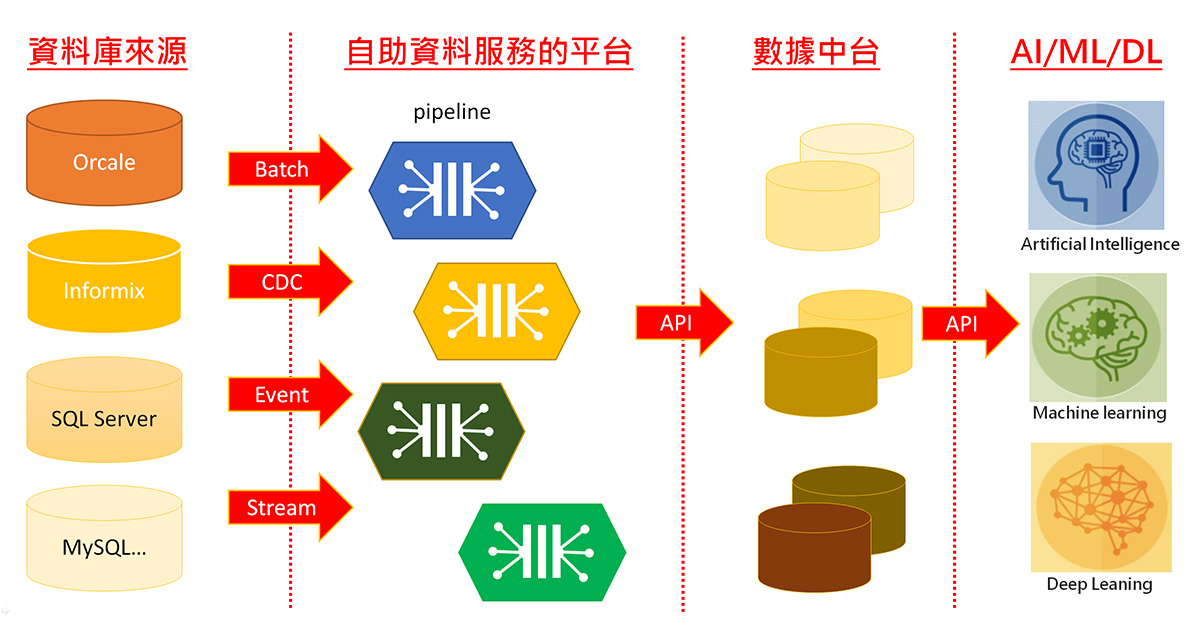
在資料聯合計算治理概念下,中台跟中台之間不但可以互相溝通,有這樣的概念以後,我們就可以支持醫療 AI 的發展需求。不管是醫院的資訊系統或是外部的開放資料系統,都可以透過這樣的方式產生不同領域的中台,再提供給 AI、機器學習(Machine Learning)、深度學習(Deep Learning)等作相關的研究分析。
資料平台典範式改革正在發生
傳統資料處理的工作方式,我稱之為 Data Mess,也就是資料雜亂,以集中方式開發,再提供給使用者,每一個人都可以針對資料去做處理,就會互相牽絆,導致工作互相耦合,可想而知就會進度緩慢,甚至交不出工作成果。
因此應該摒棄傳統的概念,改用現代化資料治理的思維 Data Mesh,也就是專業分工自動化,每一個科別都有自己設定資料轉置管線的架構量子,各自負責轉移資料來源提供的資料,如民國轉西元、字串轉數字等各自不同的領域,再快速的交付給使用者。
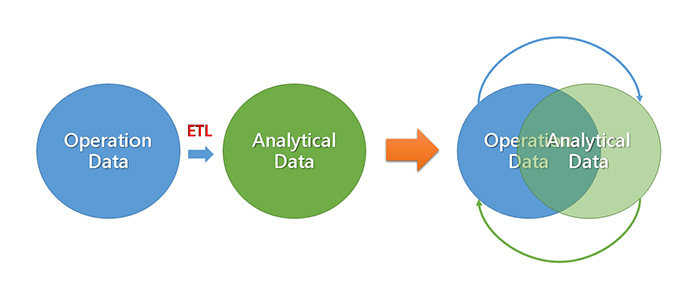
每一個架構量子就是每一個 pipeline,只要在它的儀表板去設定今天要做什麼,它就可以乖乖的幫你做好。所以未來整個資料的典範轉移,或許我們已經不用從日常交易資料(Operation Data)透過 ETL 彙總到分析資料(Analytical Data),而是可能會變成將 Operation Data 及 Analytical Data 整合在一起,變成資料即產品的概念,就不再需要每個月或半年去將線上交易資料 ETL 到線上分析資料。
[ 推薦閱讀:孫培然專欄所有文章 ]
整個資料平台的演進,從最早 1980 年的資料倉儲(Data Warehouse),逐步演進到 2000 年的資料湖(Data Lake),以及 2010 年的雲端資料平台(Cloud Data Platform),再到 2020 年的資料湖倉(Data Lakehouse),在這數十年以來,耗費鉅資建設的資料平台,卻難以獲得預期收益。
所以從 2021 年開始,我們何不拋棄前面集中式的概念,改用微服務架構的概念,用分散式的架構思維取代單體式的集中式架構,把資料下放給使用者,做到「資料即產品」,引發一次典範式變革 — Data Mesh 。
(本文授權非營利轉載,請註明出處:CIO Taiwan)











